[Reading Time: 16 minutes]
Volevi fottere l’algoritmo?
Se vuoi fregare l’algoritmo sappi che LUI ha già fottuto te.
Con la caparbietà del muflone, notissimo quadrupede cornuto, cerco di farvi capire il perché non è possibile perculare l’algoritmo.
Perché non esiste modo!
Quello che NOI chiamiamo “L’Algoritmo” in realtà sono migliaia di algoritmi dedicati a specifici processi che lavorano per automatismo e sinergia reciproca.
Creano correlazioni, determinano discriminanti, misurano gradi di relazione e di comportamento su tutti gli aspetti possibili e immaginabili del Social Network.
Al momento di questa analisi che segue se ne rintracciavano circa 8000 e tutti “Patented” e solo nel caso di F.
È semplice.
Parliamo di fabbriche che basano tutta la propria potenza sul “lavoro gratuito” degli users, dove Le Persone sono l’Oggetto del Lavoro e il Lavoro in quanto tale, viene svolto dalle macchine:
Gli algoritmi.
Facciamo un rapido calcolo:
Prendiamo ad esempio “F”: Statista riporta che in Q3 2021 presenta 2.91 miliardi MAU (monthly active users) e se calcoliamo tuti quelli che usano le app della “famigghia” si arriva quasi a 3.9 miliardi in Q1 2021.
Assumiamo per scontato (il valore è aleatorio ma di riferimento) che, in media, ogni users spenda approssimativamente 50 minuti sulla piattaforma su base giornaliera (chiaramente possono essere 0 minuti o 100 minuti in relazione alla tipologia di utente determinata principalmente dall’età, la nazionalità, il mestiere ecc. ecc.)
Conto della massaia dell’algoritmo:
50 minuti X 30 giorni X 3.9 miliardi MAU = 5.850.000.000.000 minuti di lavoro GRATUITO ogni mese
la bellezza di…. 70.200.000.000.000 di minuti spesi a lavorare gratis per la piattaforma, su base annuale e a livello planetario.
1.170.000.000.000 di ore lavoro/uomo totalmente gratuito!
(poi dovremmo levare le ore “lavorate” da bot e affini ma voglio generalizzare e lavorare gratis non basta perchè alcuni pagano anche per esserci.)
A “Noi” piace lavorare gratis e ci “piace” anche essere condizionati dalle nostre stesse scelte comportamentali e dalle scelte comportamentali dei cluster di users nei quali siamo inseriti.
Chi ci ha rinchiuso dentro i cluster?
Gli algoritmi.
[Un cluster è una tecnica di campionamento impiegata nell’analisi di mercato e fondata sulla divisione di una popolazione in gruppi omogenei]
Quindi in teoria, dovremmo guardarci da tutti! Ma come cazzo si fa?
Che vita dimmerda è?
Anche da parenti, fratelli, sorelle, fidanzate, fidanzati, mogli e mariti ecc.ecc.
Quello che loro diranno e faranno condizionerà anche la nostra vita Social (vista con gli occhi degli algoritmi).
Tutti siamo stati raggruppati in cluster, sia in modo diretto e volontario che per correlazione indiretta e apparentemente occasionale.
L’algoritmo è stato creato per sapere tutto di Noi e lo fa benissimo.
Come USERS siamo solo dei presuntuosi imbecilli senza speranza e senza scampo.
È per questo che molti professionisti di settore si spruzzano di vernice cromata la bocca e il naso, schiacciando l’acceleratore a manetta e andando incontro al Valhalla mentre urlano:
” Ammirami! Ammiramiiiii! ”
Non è un concetto chiaro “per tutti” e se non me lo blastano come fanno spesso, il video che trovate in questo articolo di DigitalSwat può aiutarvi a capire bene come funziona la faccenda dell’Enteroclisma Digitale di cui ho accennato diverse altre volte.
“Non vi nascondo che fu proprio questo video che sancì il mio personale “salto del fosso” con l’addio definitivo ad ogni forma di entusiasmo e benevolenza verso i Social Network.”
Un conto erano le deduzioni dovute all’esperienza di uno stronzissimo operaio del web (che sarebbi IO) e un conto è una bella spiegazione fatta da gente che studia esattamente questi fenomeni da un punto di vista oggettivo e non partigiano come molti invece ancora si ostinano a fare.
Forse perché sono serbi?
Forse perché sono bravi?
Boh.
Perchè vi ostinate sempre a stare dalla parte di chi comanda?
Non è stancante? Non è noioso?
Per molti, è talmente attraente da non desistere mai e come bravi discepoli e sacerdoti di una chiesa apocrifa, vanno evangelizzando le umane genti con le loro benevoli menzogne di successo.
OK, bene. Il gioco è bello quando dura poco: Fatela finita!
Chiaramente questo video lo avevo già visto diversi anni fa e non è affatto nuovo, anzi è “vecchio”.
Oggi le cose sono tranquillamente ancora più evolute e complesse ma per grandi linee, il principio resta lo stesso.
Questa di cui parliamo è un’elaborazione che risale al 2016 (momento saliente per chi ha vissuto professionalmente la piattaforma in oggetto) a cura della Panoptykon Foundation con la collaborazione del British Council e dello Share Lab che cominciò a circolare nel 2017 ma ci sono diverse dinamiche ricorrenti e perfettamente rappresentate.
Tutto ciò che è tracciabile, determina analisi di status e analisi predittive che chiaramente piacciono tanto al marketing, alla finanza, alla politica, ai ricercatori, ai governi…. a tutti.
Ogni MammaSantissima del web gode tantissimo con questi meccanismi di tracciamento globale, quindi basta pagare e si può accedere a tutte le immense risorse dovute alle mega aggregazioni di dati e i Social Network, infatti, li vendono.
Del resto servono anche per addestrare le Intelligenze Artificiali sempre più velocemente e sempre meglio, al punto che noi users siamo solo la mangiatoia nella quale l’AI mangia senza saziarsi mai.
Mettetevi bene in testa questo concetto:
⬇️
Ogni aspetto della nostra “vita” digitale è perfettamente tracciabile e se è tracciabile si può correlare. Se si può correlare si può computare.
⬆️
Tutto chiaro?
Noi viviamo in un giardino fiorito con tante farfalline colorate e recintato da un bel muro ma abbiamo un problema:
🔴 C’è solo una porta e si è chiusa alle nostre spalle. Si entra e non se ne esce
Cosa conosce l’algoritmo? Tutto.
Non si può mentire all’algoritmo perché ci conosce meglio di quanto NOI si conosca noi stessi.
🔹 Sanno le nostre idee politiche? Sì
🔹 Sanno i nostri gusti in qualsiasi campo? Sì
🔹 Sanno chi frequentiamo, dove sta e cosa pensa? Sì
🔹 Sanno che capacità economica abbiamo? Sì
🔹 Sanno di cosa parliamo? Sì
🔹 Sanno che genere, colore, gruppo etnico rappresentiamo? Sì
🔹 Sanno che stato d’animo abbiamo? Sì
🔹 Sanno che propensione all’acquisto abbiamo? Sì
🔹 Sanno dove stiamo, dove andiamo e perché? Sì
🔹 Sanno di cosa parliamo sui sistemi di messaggistica appartenenti alla “famigghia”? Sì
🔹 Sanno se siamo “veri” o se stiamo mentendo? Sì
🔹 Sanno se siamo account originali o dei fake? Sì
🔹 Sanno cosa andiamo a cercare sul web e cosa invece evitiamo di approfondire? Sì
🔹 Sanno cosa guardiamo fisicamente sui nostri device? Sì
🔹 Sanno come chiuderci in un recinto specifico o farci sparire? Sì
🔹 Sanno manipolare la percezione che abbiamo della realtà e della verità delle cose? Sì
🔹 Sanno prevedere cosa andremo a fare, vedere, dire e come andremo a reagire? Sì
🔹 Sanno come metterci davanti esattamente tutto ciò che “ci piace”? Sì
🔹Sanno cosa metterci davanti tutto ciò che ci fa incazzare e ci porta allo scontro “Noi” contro di “Voi”? Sì
🔹 Sanno aggregarci come le pecore in modo da convincerci che “Tutti dicono che…”? Sì
🔹Sanno da quali device ci colleghiamo? Sì
🔹Sanno quali device usano le nostre connessioni? Sì
🔹Sanno quanto tempo siamo connessi e da dove? Sì
🔹Sanno gli IP di ogni device e connessione in uso? Sì
🔹Sanno come includerci o escluderci da un determinato contesto di relazioni sociali? Sì
Che faccio vado avanti?
Da qui in poi IL PIPPONE prende in considerazione l’immensa quantità di algoritmi che determinano l’operatività di “F” in quanto considerato la piattaforma più vasta e al momento disponibile oltre che la più “antica”.
Il fatto che sia disponibile da molti anni ne consente una disamina più attendibile.
Come funziona la fabbrica dei dati dell’algoritmo di F?

Quattro livelli di operatività separati ma totalmente interpolati tra loro e diversi “sotto-livelli” coordinati e interdipendenti.
Il tutto avviene alla velocità del fulmicotone e da qualche parte, in profondità, dentro le macchine algoritmiche si annidano nascoste nuove forme di potenziale violazione dei diritti umani, nuove forme di sfruttamento e meccanismi di manipolazione su larga scala che influenzano miliardi di persone ogni giorno.
E il processo procede inesorabile ed efficientissimo:
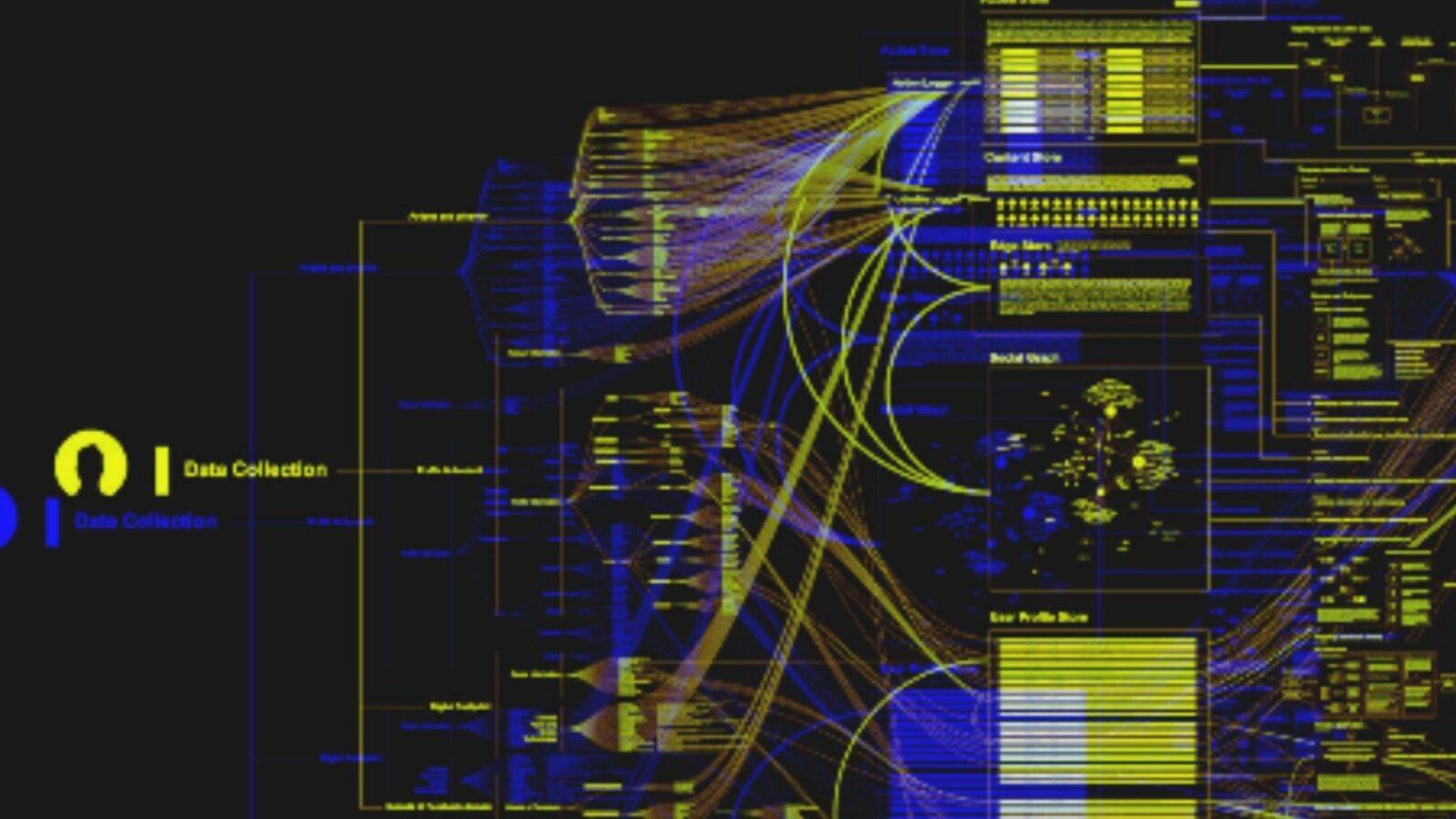
1) Data Collection
- Data Collection: Action and Behavior
- Data Collection: Account & Profile Information
- Data Collection: Online Trackers
- Data Collection: Apps Mobile Permission

Ogni like, ogni passo e movimento che facciamo, ogni foto che carichiamo, ogni evento a cui partecipiamo, viene registrato e archiviato da F, nei propri database.
Ci sono tutte le interazioni, i contenuti creati o caricati, le pagine visitate e praticamente tutto, tutto ciò che facciamo su F e anche COME lo facciamo a livello tecnico pratico: dove mettiamo le dita e tappiamo sullo smartphone o come usiamo il puntatore sul PC…. qualsiasi cosa, anche se usiamo strumenti di cattura immagine dallo schermo ecc.


Oltre le informazioni personali e comportamentali sulla piattaforma, ogni volta che visitiamo i siti web che usufruiscono dei F. Services, F. riceve informazioni sulla nostra visita perché associa l’IP del nostro device alla traccia di navigazione e queste informazioni diventano parte integrante del processo di profilazione.
🔴 Sia nel caso in cui noi si sia in stato di Log In, sia nel caso in cui si sia in stato di Log Out.
Un processo senza fine perfetto per creare un’immagine chiara di chi siamo, cosa ci piace e quali sono i nostri modelli comportamentali.

Non dimenticare mai tutte le autorizzazioni che concedi al momento dell’installazione delle app sul tuo smartphone e non dimenticare che le app sono tutte interlacciate tra di loro.
2) Storage
- Action Store
Ogni clic, “mi piace”, condivisioni e praticamente tutto ciò che facciamo su F. viene raccolto da un registratore di azioni e archiviato nell’Action Store. L’action store conserva informazioni che descrivono le azioni degli utenti, nonché le azioni eseguite su siti Web di terzi che comunicano informazioni a F.
- Gli utenti possono interagire con vari oggetti, gestiti da F., e queste interazioni sono memorizzate nell’Action Store. Esempi di azioni o interazioni includono: commentare post, condividere link, taggare oggetti e fare il check-in in luoghi fisici, commentare un album fotografico, trasmettere messaggi a un altro utente, partecipare a un evento, unirsi a un gruppo, diventare fan di un brand page, creazione di un evento, autorizzazione di un’applicazione, utilizzo di un’applicazione, interazione con un annuncio pubblicitario e partecipazione a una transazione.
- Content Store Il Content Store memorizza oggetti che rappresentano vari tipi di contenuto come post di una pagina, un aggiornamento di stato, una foto, un video, un collegamento, un elemento di contenuto condiviso, un risultato di un’applicazione di gioco, un evento di check-in presso un’azienda locale, un marchio pagina o qualsiasi altro tipo di contenuto. Gli oggetti possono essere creati dagli utenti o in alcuni casi ricevuti da applicazioni di terze parti (altri siti Web o app).
- Edge Store L’Edge Store memorizza le informazioni che descrivono le connessioni tra utenti e altri oggetti. Alcuni “edges” possono essere definiti dagli utenti, consentendo agli utenti stessi di specificare le proprie relazioni con altri users. Altri edges vengono generati quando gli utenti interagiscono con oggetti, come esprimere interesse per una pagina, condividere un collegamento con altri users e commentare i post fatti da altri. L’edge store memorizza anche informazioni aggiuntive, come punteggi di affinità per oggetti, interessi e altre informazioni generate dall’elaborazione algoritmica.
- Social Graph In questo caso è bene conoscere la teoria degli “Objects” anche conosciuti come “Nodes” e delle “Connections” che mettono in relazione i nodi e vengono anche definite “Edges”.Sono le basi del Social Graph il vero cuore della struttura.”La struttura delle strutture”, un unico sistema che raccorda tutto e tutti.


Per esempio: Tutte le nostre azioni sulla piattaforma sono registrate su Action and Content Logger che alimenta gli store di Action e Content con nuovi dati, ampliando costantemente la banca dati su di noi e che è di proprietà di F. e potenzialmente condivisa con molti altri.
- User Profile Store i nostri dati e le informazioni che condividiamo volontariamente nella sezione delle informazioni sul profilo, sono archiviate in Profile Store.

3) Algorithmic Processing 4) Targeting
Tutti inostri dati servono esclusivamente a intuire quale tipo di pubblicità può essere più calzante ed efficace, in relazione ai nostri modelli comportamentali.

Sono 3 i perni su cui si articola questa meccanica:
- Action Interest Extractor i log vengono caricati nell’Action Interest Extractor. L’elenco degli interessi dell’utente specifico viene determinato basandosi esclusivamente sui dati dell’Action log, ovvero le sue attività (clic, Mi piace, commenti, condivisioni, ecc…). Succesivamente, l’elenco degli interessi viene inoltrato al Fuzzy matcher, sottoforma di query.
- Item Concept Extractor è l’algoritmo che estrae la pertinenza dei contenuti dello users e si raccorda con l’Ad Server che comincia a proporre tipologie di pubblicità “pertinenti”.
- Fuzzy Matcher è l’algoritmo che mette in relazione gli interessi dello users con la pertinenza estrapolata dai contenuti dello user stesso e decide quale pubblicità è più pertinente, la cerca e la rilascia allo users.
Vi ricordate il Content Store?

Ci sono due aspetti rilevanti del targeting basato sul contenuto. Il primo sono gli argomenti, il secondo le parole chiave.
Quando un utente pubblica un qualche tipo di contenuto su F, c’è un motore di estrazione degli argomenti che identifica uno o più argomenti associati al contenuto.
Per associare gli argomenti al contenuto, il motore di estrazione lo analizza e identifica i termini di ancoraggio inclusi nel contenuto e ne determina il significato.
Utilizzando l’argomento estratto, un algoritmo definisce un elenco di parole chiave e associa loro uno o più valori attesi. L’algoritmo utilizza le informazioni sull’utente per determinare i valori associati alle parole chiave candidate nell’elenco.
I valori assegnati vengono utilizzati per classificare le parole chiave candidate, scegliendo la classificazione più alta in quanto definisce il contenuto in modo più preciso.
Quando si sceglie quale contenuto, ovvero gli annunci verranno offerti all’utente in futuro, l’algoritmo utilizza i collegamenti creati tra l’utente e le parole chiave del contenuto.
Un input importante per il targeting basato sui contenuti proviene anche dal Action Store ed è correlato ai segnali negativi del targeting degli annunci.
Questo è in effetti un insieme di contenuti verso cui l’utente potrebbe avere un sentimento negativo e viene utilizzato per etichettare gli annunci che gli utenti non vorrebbero vedere.
Quando F. determina, in base alle azioni dell’utente, che non gli piace un particolare oggetto (contenuto), determina l’argomento dell’oggetto e associa loro un sentimento negativo.
L’associazione tra opinioni negative e argomenti viene utilizzata per ridurre la probabilità che un annuncio corrispondente a tale argomento venga offerto all’utente.
Sempre chiusi dentro a cluster precisi e definiti.
Più il cluster è piccolo e circoscritto più siamo facilmente identificabili e profilabili. Per approfondire questo punto, chiedetemelo di persona e parliamo per 4 giorni. Ecco perchè spesso e volentieri definisco ogni forma di raggruppamento “Il male assoluto” e la morte del Social Network.
Il raggruppamento in cluster è la meccanica DIVISIVA che compromette il vero senso Social del Network e lo rende semplicemente una rete da pesca a maglie molto strette.

I dati importanti per un targeting preciso vengono raccolti formando strutture logiche degli utenti.
F. raggruppa gli utenti che condividono un particolare attributo in una struttura chiamata “Seed Cluster”.
Una volta creato un seed cluster, viene recuperato un insieme di altri utenti o oggetti a cui l’utente è correlato.
All’interno di questi insiemi, un algoritmo determina se gli utenti nell’insieme condividono lo stesso attributo dell’utente principale. Il processo di determinazione si basa sulla dichiarazione esplicita dell’utente secondario, sull’analisi delle sue connessioni e utilizza un algoritmo di random walk. I risultati vengono utilizzati per decidere se l’utente secondario può essere associato anche al cluster.
Di conseguenza, viene stabilito un cluster di targeting e può essere utilizzato per indirizzare gli utenti e mostrare loro annunci specifici.
La credibilità di questi cluster viene testata misurando le percentuali di clic degli utenti nel cluster per un particolare annuncio o misurando il feedback negativo degli utenti nel cluster. Inoltre, gli utenti possono essere inseriti in un cluster in base alle loro interazioni con pagine, applicazioni, ecc.
Il processo di formazione di gruppi e sottogruppi utilizza diversi moduli.
Innanzitutto, il modulo di selezione dell’utente “seed”, che raccoglie informazioni su potenziali altri utenti “seed” (primari) e crea un cluster “seed” di utenti che condividono una particolare affiliazione, interesse o caratteristica.
Nella prima fase l’algoritmo seleziona gli utenti che hanno esplicitamente dichiarato questi attributi sui propri profili (come una pagina o i like). Tuttavia, le attività, come Mi piace, commenti, check-in, ecc. relative all’utente possono essere utilizzate per il clustering.
Un secondo modulo viene utilizzato per creare sottogruppi in base ai membri del gruppo (utenti già nel cluster), esplorando le loro attività e attributi e verificando se potrebbero far parte del gruppo.
Il processo di raccolta dei dati per questi utenti secondari è simile a quello utilizzato per gli utenti seed.
Il modulo di analisi delle entità viene utilizzato per determinare gli attributi degli utenti in base alle loro interazioni con pagine o applicazioni.
Ad esempio, se qualcuno sostiene un determinato partito politico, l’algoritmo presume che potrebbe essere interessato a un certo tipo di auto, perché la maggior parte degli utenti che utilizzano un’applicazione F che mostra i punti vendita più vicini per dette auto, supporta tale partito politico.
Ciò che fa questo modulo è raggruppare le persone in base agli oggetti con cui interagiscono e al tipo di utenti che interagiscono più spesso con tali oggetti.
Alcuni attributi dell’utente possono essere determinati valutando le loro connessioni ad altri utenti. Questo viene fatto dal modulo di punteggio analitico.
Questo modulo determina attributi particolari dell’utente valutando le sue connessioni con altre persone.
Ad esempio, se un utente ha poche connessioni deboli con altri utenti a cui piace il vino bianco e legami più forti con utenti a cui piace il vino rosso, questo modulo si baserà sulla forza delle connessioni (probabilmente sulla base di interazioni reciproche, check-in, tag ecc) considererà l’utente principale come uno a cui piace il vino rosso.
Una volta determinati attributi dai quattro moduli summenzionati, un modulo di definizione del cluster di targeting genera un cluster di utenti che condividono gli stessi attributi. I cluster vengono utilizzati per offrire tipi specifici di annunci, ma anche per il targeting specifico di contenuti che è probabile che l’utente apprezzi.
In questo modo, oltre a generare entrate, F controlla anche il flusso di informazioni verso l’utente, in base alle preferenze, che un insieme di algoritmi ha stabilito.
In un certo senso, questa potrebbe essere considerata: CENSURA.
Il processo di formazione di gruppi e sottogruppi, utilizzando i moduli di cui sopra, come un flusso completo ha diversi passaggi. Innanzitutto gli utenti sono strutturati in sottogruppi basati su un attributo simile; quindi si individua un centroide (un utente centrale) del gruppo, e attraverso di essi si individuano le caratteristiche dell’intero gruppo.
Tutti gli utenti nei sottogruppi vengono quindi classificati in base alla somiglianza dei loro attributi, a quelli dell’utente centrale, ovvero il sottogruppo.
Infine il sottogruppo è etichettato come unità intera e compatta.
Considerato che il meccanismo è assai complesso, riporto di seguito diverse altre meccaniche di targeting che consiglio di approfondire:
- Targeting users based on events Questo algoritmo esegue il targeting degli eventi in base a diversi criteri. Il primo e più semplice criterio che potrebbe indicare un’associazione di un utente ad un evento è l’opzione RSVP sugli eventi creati su F. Tuttavia, poiché gli utenti possono rispondere sì, ma non partecipare a un evento, l’algoritmo può calcolare se parteciperanno davvero all’evento in base al punteggio di partecipazione precedente, al numero dei loro amici presenti e alla cronologia generale dell’evento.
Inoltre, l’algoritmo utilizza altri input, come il check-in presso la sede dell’evento, il caricamento di una foto dei biglietti per l’evento, la registrazione dell’acquisto dei biglietti su un sito Web esterno o il tag dell’evento in un post. Il targeting per eventi viene utilizzato su eventi su tutte le scale, da piccoli eventi privati a eventi globali.

- Targeting objects to users based on search results in an online system Questo algoritmo utilizza la query che gli utenti immettono nella casella di ricerca su F. Lo scopo di questo algoritmo è offrire all’utente annunci che corrispondono alla sua query di ricerca.
Quando lo user inserisce la query nella casella di ricerca, vengono compilati i risultati corrispondenti alla query, mentre l’algoritmo cerca di riconoscere un nodo strutturato nella query e nei risultati.
Quindi, recupera gli annunci che corrispondono al nodo strutturato riconosciuto e allo stesso tempo recupera le informazioni sull’utente.
Dopo aver abbinato gli annunci alle informazioni dell’utente, ovvero gli attributi, determina quali annunci devono essere mostrati con i risultati della query.
Questo accade praticamente mentre l’utente digita la query, quindi è abbastanza difficile percepirla come qualcosa di così ben strutturato.
- Routine estimation Questo algoritmo determina le routine di un utente analizzando la geolocalizzazione di un utente in un periodo di tempo a intervalli orari.
L’algoritmo utilizza i dati sulla geolocalizzazione dell’utente forniti da dispositivi mobili, come smartphone, tablet o laptop, o meglio sensori installati in questi dispositivi, ad esempio sensore GPS, giroscopio o bussola; l’app F installata sul dispositivo raccoglie i dati necessari e li invia all’algoritmo.
Successivamente, l’algoritmo analizza la ripetizione o l’utente che si trova nella stessa posizione a una determinata ora in un determinato giorno della settimana.
L’algoritmo raggruppa quindi questi centroidi di geolocalizzazione; successivamente i cluster sono etichettati da un luogo che corrisponde ai centroidi di geolocalizzazione nel cluster.
In questo modo, l’algoritmo può determinare dove vive l’utente, dove lavora, se va al mercato del contadino il sabato mattina, se va in palestra e con quale frequenza ecc.

- Inferring household income for users e qui si parla di fare i conti in tasca alle persone.
L’algoritmo mappa un utente in una particolare fascia di reddito. Ciò avviene attraverso l’analisi delle informazioni fornite dall’utente, ad esempio posizioni lavorative attuali e passate, istituto di istruzione attuale e passato frequentato, eventi della vita, relazioni familiari e stato matrimoniale.
Tuttavia, poiché gli utenti hanno la possibilità di fornire informazioni false a F, questo algoritmo analizza ulteriormente il comportamento dell’utente, i siti Web visitati, gli acquisti effettuati online, ecc.
L’algoritmo utilizza diverse tecniche per mappare l’utente in una particolare fascia, inclusa l’analisi delle immagini per riconoscere i marchi che l’utente indossa sulle foto caricate, la frequenza con cui utilizzano i nomi dei marchi nei post e nelle ricerche, ecc.
Queste informazioni vengono quindi utilizzate per consentire agli inserzionisti di raggiungere più facilmente il loro gruppo target appropriato in base al reddito.
Inoltre, l’algoritmo di apprendimento automatico ha la capacità di rilevare quando gli utenti hanno fornito informazioni errate o hanno dimenticato di aggiornare le proprie informazioni, come il cambio di posto di lavoro, il trasferimento in un’altra città stato civile e simili.
- Comparing Financial Transactions Of Users Ciò che fa questo algoritmo è confrontare le abitudini di acquisto di un utente rispetto a un gruppo di utenti a cui l’utente può essere associato condividendo attributi simili, come età, posizione, livello di istruzione, posizione lavorativa ecc.
Gli algoritmi analizzano le query di ricerca, le visite a siti Web esterni e altri tipi di transazioni all’interno di F e su siti Web di terzi.
Utilizzando questi dati, l’algoritmo può fornire all’utente l’analisi delle precedenti transazioni, ma può anche prevedere le spese future, ad esempio può prevedere quanto spenderebbe un utente per i viaggi confrontando le sue transazioni precedenti con altri utenti che condividono interessi simili, hanno hanno la stessa età e vivono nella stessa città dell’utente principale.

- Associating cameras with users of a social networking system Questo algoritmo associa gli utenti di F sulla base di immagini e/o video realizzati utilizzando la stessa fotocamera, ovvero il dispositivo.
Quando foto o video vengono caricati su F, l’interfaccia utente, la firma della fotocamera “è rossa”, l’algoritmo la percepisce e funge da punto di connessione per gli utenti che caricano foto o video ripresi utilizzando lo stesso dispositivo, ovvero la fotocamera.
Questo può essere utilizzato per rilevare account falsi, un utente che ha più account; ma anche ai fini di un grafico sociale, ad esempio consigliare amici, dare priorità ai feed di notizie, ecc.

Dobbiamo tutti essere utenti di qualità e garantire la migliore profilazione. Capito?
Più precisi sono i profili utente, migliore sarà il prodotto offerto agli inserzionisti. Il prodotto finale dell’economia della sorveglianza di F è una profonda conoscenza dei tuoi interessi e modelli di comportamento, la conoscenza esatta di chi sei veramente e la previsione di come ti comporterai in futuro, rinchiuso in un profilo utente.
Dobbiamo essere venduti come users attendibili altrimenti non serviamo a niente.
La chiave per capire di più come lavorano le piattaforme è andare a vedere la tipologia di algoritmo che hanno registrato come PATENTED e analizzare cosa fanno nello specifico.
Essendo migliaia di algoritmi per ogni piattaforma diventa un lavoro mastodontico ma le esemplificazioni sopra riportate ne sono un esempio utile a comprendere i meccanismi.
Di seguito alcuni esempi ulteriori elencati in estrema sintesi:
- Basic and targeting based on connctions

- Targeting based on demographics

- Targeting based on users interests

- Targeting based on Behaviour

L’opzione di targeting più “intrigante” in questo segmento è: la sezione All frequent travelers .
(in patent WO 2014123982 A3 Routine estimation)
Qui F offre il targeting di viaggiatori d’affari e internazionali, pendolari, utenti che sono attualmente in viaggio o utenti che sono tornati dal viaggio una o due settimane fa. Questo brevetto spiega il metodo analitico dei dati di geolocalizzazione degli utenti raccolti dai dispositivi in un periodo di tempo a intervalli orari.
L’algoritmo analizza la ripetizione, ovvero l’utente che si trova nella stessa posizione a una certa ora in un determinato giorno della settimana. L’algoritmo raggruppa quindi queste geolocalizzazioni e le etichetta in base a un luogo.
L’algoritmo può determinare dove vive l’utente, dove lavora, se è pendolari o sta attualmente viaggiando all’estero.
Un altro segmento interessante (o inquietante secondo la Vostra sensibilità) è quello relativo all’analisi delle transazioni finanziarie. Analizzando i brevetti:
e
- Comparing Financial Transactions Of A Social Networking System User To Financial Transactions Of Other Users (US 20140222636 A1)
possiamo scoprire come F raggruppa gli utenti in una determinata fascia di reddito.
Ciò avviene attraverso l’analisi delle informazioni fornite dall’utente, ad esempio posizioni lavorative attuali e passate, istituti di istruzione attuali e passati che hanno frequentato, eventi della vita, relazioni familiari e stato matrimoniale, comportamento dell’utente, siti Web che visita, acquisti che effettua online.
L’algoritmo utilizza diverse tecniche tra cui l’analisi delle immagini per riconoscere i marchi che l’utente indossa sulle foto caricate, la frequenza con cui usano i nomi dei marchi nei post e nelle ricerche, ecc.
Tutta questa analisi su diversi aspetti degli algoritmi è effettivamente vecchia! (ma utile)
È vecchia perchè i brevetti diventano pubblici dopo 2 anni che sono stati registrati e in 2 anni, nel mondo digitale, può succedere di tutto e le piattaforme sono in TUNE-UP continuo. Possiamo quindi dare per scontato che tutti gli schemi operativi che abbiamo visto fino ad ora sono sicuramente vetusti.
Lo scopo è capire la logica, acquisire consapevolezza e scegliere. Alcuni potranno usare questi input per migliorare le proprie performance sulle piattaforme, altri… ne faranno il loro step finale per darsi all’agricoltura e all’allevamento estensivo oltre che a fare un orto bello florido e rigoglioso.
Dipende dai gusti.
Per continuare l’approfondimento
Non nascondo che è stato un approfondimento “gravoso” ed estraniante e francamente pesantissimo. Per poter meglio comprendere gli schemi riportati fino a qui, consiglio la lettura della seguente trilogia di link spaccacervello:
Immaterial Labour and Data Harvesting Facebook Algorithmic Factory (1)
⬇️
Human Data Banks and Algorithmic Labour Facebook Algorithmic Factory (2)
⬇️
Quantified Lives on DiscountFacebook Algorithmic Factory (3)
e ringrazio Share Lab per il lavoro pazzesco che hanno portato a termine e che sto ancora analizzando.
Menomale và, mi sento davvero meno “solo”.
Vado a fumare.
[Tutte le immagini usate nell’articolo sono di proprietà dello Share Lab. Le descrizioni del funzionamento in termini tecnici sono riprese dalla versione originale]

85.000 ore sui Social Network come SMM e Social Media Strategist poi è venuto via schifato e deluso e oggi è passato dall’altro lato della barricata e si definisce: Humane Technologist. Ha avuto almeno 4 vite diverse: partito musicista, ha studiato Scienze Agrarie e Economia, è stato produttore discografico, produttore di eventi, gestore di locali, consulente audio e fonico in teatro, si è chiuso in casa per due anni per approfondire le tematiche del business planning e del marketing planning, sui programmi della Palo Alto Software. Poi per anni Property Manager a Londra con una propria azienda…
Chiedete a lui cosa significa vivere così
I contenuti di questo post sono prodotti dall’autore che se ne assume ogni responsabilità.
| Riproduci | Copertina | Rilascia Etichetta |
Titolo del brano Traccia gli autori |
|---|